How ChatGPT (AI) Understands You (Almost Like a Human)
Introduction
When you type something into ChatGPT, it feels like you’re talking to a smart friend who magically “gets” English, Hindi, Hinglish, emojis, sarcasm - just everything.
But here’s the twist:
AI doesn’t understand English.
Not even a little.
And that’s where things get interesting.
We speak in language.
AI speaks in numbers.
So every conversation sits on top of a giant translation layer that quietly works behind the scenes, turning your words into math and math back into words - all in milliseconds.
Before we get into the heavy-duty AI machinery, let’s slow down and understand the basics.
Language → Meaning: How Humans Do It
Imagine someone picks up a Hindi-to-English dictionary and tries to translate:
“Kaise ho aap?” → “How are you?”
Even without a dictionary, your brain knows the meaning instantly.
You don’t spell out K-A-I-S-E.
You don’t break it into syllables.
Your brain jumps straight to meaning - a feeling, an understanding, a memory.
When you hear “chai”, you don’t see “C-H-A-I”.
You sense warmth, aroma, comfort, maybe even a rainy evening.
This is how humans process language:
We hear words
We convert them to meaning
Meaning triggers a mental pattern
AI tries to do something similar - but with math instead of neurons.
Step 1: Tokenization → Breaking Words Into Pieces
Before AI can understand anything, it needs to chop your text into tiny units called tokens.
The sentence:
“How are you doing today?”

might become something like:
[“How”, “are”, “you”, “doing”, “today”]
Think of tokenization as the model’s way of saying:
“Let me break this sentence into pieces that I can turn into numbers - the form the model can actually understand.”
For example: Here’s how some of those tokens look:
“How” → 5299
“are” → 553
“you” → 481
“doing” → 5306
“today” → 4044
Under the Hood: The Tokenizer Code

The Actual Tokens

These IDs now move into the next step: embeddings → where actual meaning gets constructed.
Step 2: Embeddings → Turning Tokens Into Meaning
After tokenization, all we have is a list of token IDs:
[5299, 553, 481, 5306, 4044]
Useful?
Not really.
Token IDs are just labels - they carry zero meaning.
The model can’t understand anything from them.
This is where embeddings step in.
What Embeddings Actually Do
Embeddings convert each token into a vector - a list of hundreds or thousands of numbers that represent the meaning of that word.
Example (conceptual):
"chai" → [-0.12, 0.58, 1.29, -0.44, ...]
"tea" → [-0.10, 0.61, 1.33, -0.40, ...]
Look at those two vectors… almost similar, right?
That’s the idea.
Words with similar meaning live close together in this mathematical space.
It’s like a giant map where:
“Kitten” is near “cat”
“dog” is near “wolf”
“Apple” is closer to “banana” than to “cat”
Embeddings = meaning.
Here’s a visual that shows exactly how tokens cluster in vector space:
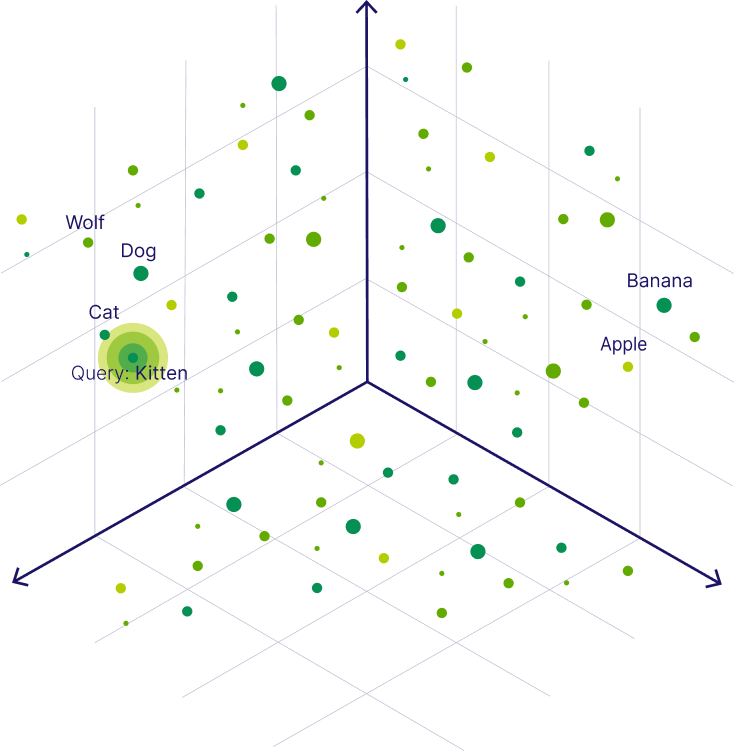
Words that share meaning appear close together in vector space.
When you hear the word “chai”:
You don’t think:
“C-H-A-I”
Your brain fires a pattern - a memory of taste, smell, warmth, maybe Baarish (Rain) vibes.
Similarly, AI stores meaning as a pattern of numbers.
Different system, same idea.
This is why embeddings are often described as the model’s “memory space.”
Tiny Code Example: Getting an Embedding
Here’s a small snippet that fetches the embedding vector for the word “chai”

What you’ll see:
The vector will be around 1536 dimensions
And the first few numbers will look random - but they encode meaning
Preview of Embedding Output
Embedding length: 1536

This long list of numbers is how the model understands your text.
Not as words.
Not as grammar.
But as pure meaning patterns.
Why This Matters
Now the model has everything it needs to actually think:
It knows what each word “means.”
It knows which words relate to each other.
It knows how words cluster together into concepts.
The next step?
Now the model knows what our words mean -
but it still doesn’t know the order in which we said them.
Because embeddings only capture meaning,
“The cat sat on the mat”
and
“The mat sat on the cat”
use the same words and would produce the same embeddings, just arranged differently.
But the model still has no way to understand:
who sat on whom
what happened first
what the sentence actually means
How does the model understand order?
That’s where Positional Encoding comes in.
Step 3: Positional Encoding → Teaching the Model Word Order
By now, the model knows:
what each word means (embeddings)
how words relate in meaning
But there’s still a major problem:
The model has no idea what order the words came in.
Embeddings capture meaning…
but not sequence.
Why Order Matters
Look at these two sentences:
“The cat sat on the mat.”
“The mat sat on the cat.”
They contain the exact same words.
They would produce the same embeddings, just arranged differently.
But the meaning?
100% opposite.
Without knowing which word comes where, the model can’t understand:
who did the action
what happened first
the actual intent of the sentence
So how do we fix this?
Positional Encoding: Giving Words a Sense of Place
To teach the model order, we add a tiny pattern to every word embedding - something like:
Word 1 → position pattern A
Word 2 → position pattern B
Word 3 → position pattern C
These patterns are created using a mathematical function
(don’t worry, we don’t need to touch the formulas - that’s deep ML engineer territory).
This function slightly shifts each embedding so the model can feel:
“I’m the first word.”
“I’m the second word.”
“I come after ‘cat’ but before ‘mat’.”
All you really need to know:
Positional encodings inject order into meaning.
It’s like giving each word a small GPS coordinate, so the model knows where it is in the sentence.
Why This Step Is Crucial
With positional encoding:
“cat” knows it comes before “sat”
“sat” knows its subject is “cat”
“mat” knows it’s the location, not the actor
Now the model can actually understand the structure of your sentence.
Meaning + Order = Understanding.
The Big Picture
Up to now, your text has gone through:
Tokenization → break into pieces
Embeddings → convert into meaning
Positional Encoding → understand order
Now the model has everything it needs to read your input properly.
So the next question is:
Once the model knows what you said and in what order…
how does it decide what to pay attention to?
That’s where Self-Attention comes in - the heart of the Transformer.
Step 4: Self-Attention → How the Model Figures Out “Who Matters?”
Now the model knows two things:
What each word means (embeddings)
Where each word is in the sentence (positional encoding)
But understanding language requires one more skill:
Knowing which words depend on which.
Because meaning is not just about the words -
it’s about their relationships.
And that’s exactly what Self-Attention does.
Why We Need Self-Attention
Take this sentence:
“He went to the bank.”
Does “bank” mean:
a place with water (river bank), or
a place with money (ICICI bank)?
The model doesn’t know…
until it looks at the other words in the sentence.
This is where the magic happens.
What Self-Attention Actually Does
Self-Attention lets every token talk to every other token and decide:
Who is relevant to me?
Whose meaning affects my meaning?
How much should I pay attention to each word?
In Hindi:
“Yaha har token ko mauka milta hai ki bhai… sentence mein kaun important hai, ek baar check karlo.”
Example That Makes It Crystal Clear
1. “The river bank was flooded.”
“bank” looks around and sees “river” → oh, water → correct meaning.
2. “The ICICI bank was closed.”
“bank” sees “ICICI” → financial → correct meaning.
Same word.
Different meaning.
Context decides.
Self-Attention is the mechanism through which this happens.
Another Example
“A dog is sleeping on a train.”
Here’s how Self-Attention works internally:
“dog” pays attention to “sleeping” → action it performs
“sleeping” pays attention to “dog” → who is doing it
“train” gives location
“on” links “sleeping” ↔ “train”
This is how the model builds relationships between words.

The Result
After self-attention, each token’s embedding becomes a context-aware embedding.
Meaning:
“bank” now knows if it’s next to a river or a financial institution
“he” knows who “he” refers to
“dog” knows it is the subject
“train” knows it provides location
The model isn’t just reading words -
it’s understanding relationships.
Self-attention takes plain word embeddings and turns them into context-aware embeddings - tokens that understand not just what they mean, but how they relate to every other word in the sentence.
Now the model has meaning + order + relationships.
But one attention head can only look at the sentence from one angle.
To truly understand language, the model needs to think from multiple perspectives at once.
Step 5: Multi-Head Attention → Understanding From Multiple Angles
Self-Attention gives the model one powerful ability:
Look around the sentence and decide which words matter.
But language isn’t a one-angle thing.
Sometimes meaning depends on:
who is doing something
what action is happening
where it’s happening
how words are connected
what the sentence structure looks like
which words indicate time, tense, or sentiment
And one attention head can only focus on one pattern at a time.
So the Transformer does something genius.
What Multi-Head Attention Actually Does
Instead of one attention head, the model uses many heads in parallel.
Each head looks at the same sentence…
but from its own unique perspective.
Examples of what different heads might focus on:
One head tracks subject → verb
One head focuses on location
One head looks for objects
One focuses on long-range dependencies (“because”, “however”, “although”)
One captures tense or timing
One watches for who refers to whom (“he”, “she”, “it”)
Think of it like a group of detectives analyzing the same scene -
each looking for different clues.
Then all heads combine their insights to form a richer understanding of the sentence.
Example
Sentence:
“A dog is sleeping on a train.”
Different heads might focus on:
Head 1 → “dog ↔ sleeping” (who is doing what)
Head 2 → “sleeping ↔ train” (action + location)
Head 3 → “on” (relation)
Head 4 → sentence structure
Head 5 → long-range context
Each head sees something different.
Together, they give the model a complete picture.
Why Multi-Head Attention Matters
Because language is complicated.
No single viewpoint is enough.
By using many attention heads at once, the Transformer becomes:
more accurate
more context-aware
better at resolving ambiguity
better at understanding long sentences
better at reasoning
This is why LLMs “feel” intelligent.
Now the model has:
Meaning (Embeddings)
Order (Positional Encoding)
Relationships (Self-Attention)
Multiple Perspectives (Multi-Head Attention)
But there’s one more critical piece inside a Transformer block:
A Feed-Forward Neural Network to refine and polish the information.
Step 6: Feed-Forward Network → Polishing the Meaning
After multi-head attention does its job, each token now has a rich, context-aware representation.
But Transformers add one more small step to make the understanding even sharper:
A Feed-Forward Neural Network (FFN).
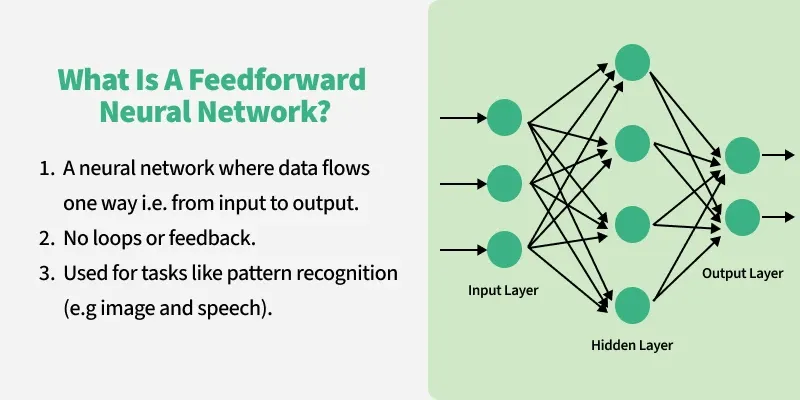
And don’t worry - this is the simplest part of the entire model.
What FFN Really Does
It takes the updated token representation…
transforms it a bit using a tiny neural network…
and sends it forward.
That’s literally it.
No loops.
No attention.
No fancy math.
Just a simple “take input → apply a formula → give output.”
Why It Exists
Think of the FFN as a mini brain inside each Transformer layer.
Attention helps tokens talk to each other.
FFN helps each token think on its own - refine itself.
Simple Analogy
Attention = “Who matters in this sentence?”
FFN = “Ok, now that I know that… let me process it internally.”
It’s polish.
Cleanup.
Refinement.
The Flow
For each token:
Take its vector
Pass it through a small neural network (just two linear layers + activation)
Output a cleaned-up representation
That’s all.
Why This Matters
Because attention gives context,
but FFN gives structure and clarity.
Together, they form one Transformer block.
Step 7: The Full Transformer Pipeline (Everything Comes Together)
Alright… deep breath.
So far, we’ve already cracked:
how text becomes tokens
how tokens become meaning
how we give words order
how tokens talk to each other
how the model thinks from multiple angles
how each token polishes its meaning
That’s A LOT.
And all of it builds up to this moment.
There’s just one thing left:
Seeing how all these pieces fit together in one single Transformer block.
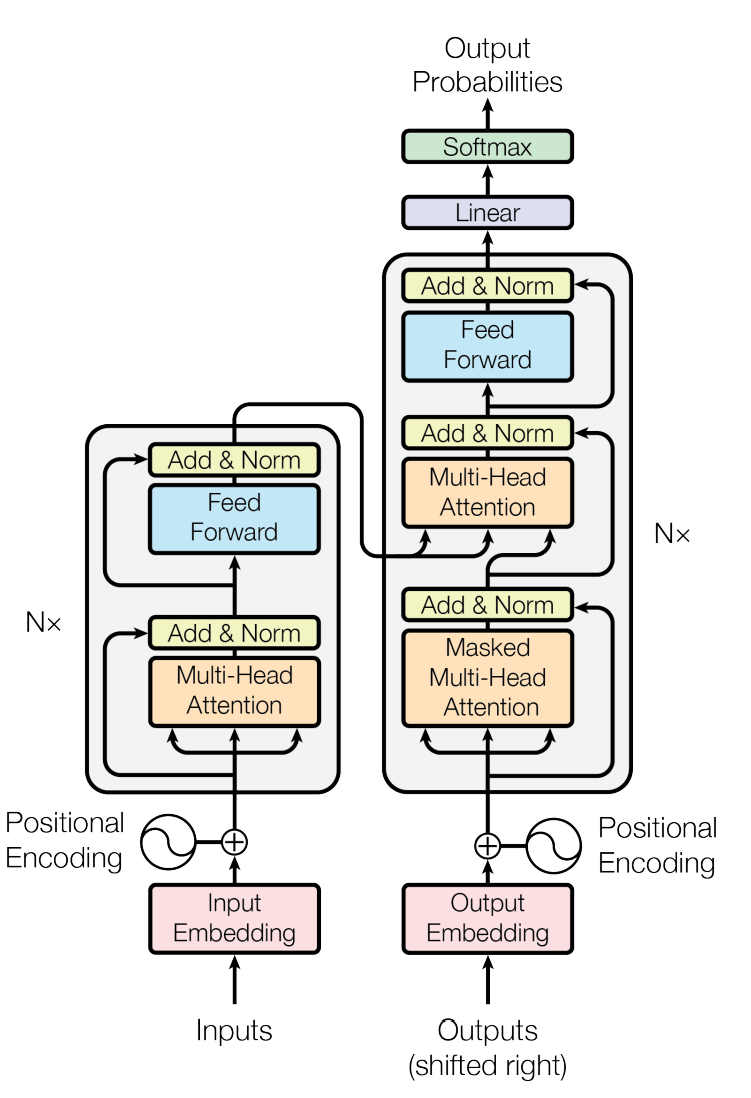
Looks intense, right?
But the best part? Now it actually makes sense to you.
Let’s break it down at high level.
What You’re Seeing
Each block (the rectangles) is made of:
Multi-Head Attention
Add & Norm
Feed-Forward Network
Add & Norm (again)
And this block is repeated N times - meaning multiple layers stacked on top of each other.
Every single layer refines your input a bit more.
Quick Note on Add & Norm
Since you’ll see it everywhere:
Add = add the original value back (residual)
Norm = normalize for stability
You don’t need the formulas - just remember:
Add & Norm keeps the model stable, smooth, and sane.
Now the final question…
We understand the internal engine.
But how does the model actually turn all this into:
“Here’s the answer to your question”?
How does the model actually take all this processing and turn it into words?
How does it decide:
which token to generate
why that token
how the next token follows
and how the full reply appears to us
That’s where Step 8 comes in.
Step 8: How the Model Generates Words (Linear → Softmax → Next Token)
We’ve finally reached the last part of the pipeline.
Your text has been:
tokenized
embedded
position-encoded
passed through attention
polished by feed-forward layers
processed through multiple Transformer blocks
Now the model has one job left:
Pick the next word. And then the next. And then the next…
LLMs generate one token at a time, super fast.
Here’s how that final decision is made.
Step 1: Linear Layer → Raw Scores (Logits)

After the last Transformer block, every token representation is pushed into a simple linear layer.
This layer does something extremely basic:
It gives a score for every possible next token in the entire vocabulary.
Not probabilities.
Not choices.
Just raw scores.
If your vocabulary has 50,000 tokens, you get 50,000 scores.
Example (conceptual):
Token options: ["I", "am", "hungry"]
Linear layer scores: [2.3, 1.2, -0.5]
Step 2: Softmax → Turn Scores Into Probabilities
Softmax takes those raw scores and turns them into probabilities that add up to 1.
Example:
logits: [2.3, 1.2, -0.5]
softmax → [0.70, 0.25, 0.05]
Now the model knows:
“I” → 70%
“am” → 25%
“hungry” → 5%
Softmax is NOT creativity or randomness.
It’s just the function that converts scores → probabilities.
Step 3: Sampling → Choose the Next Token
Now the model must pick one token from the probability distribution.
There are different ways to do this:
1. Greedy Sampling (simple + predictable)
Choose the highest probability token.
Good for factual answers.
Bad for creative writing.
2. Temperature (controls randomness)
Low temperature → safer, more focused text
High temperature → more creative, more surprising
Example:
Temperature 0.1 → “The sky is blue.”
Temperature 1.0 → “The sky is a canvas of shifting moods.”
3. Top-k / Top-p (smart creativity filters)
Limit the model to the top few likely tokens so it doesn’t go crazy.
These strategies shape how “creative” or “serious” the model feels.
Step 4: Repeat… again… and again
Once the model chooses the next token:
It appends it to the sequence
Feeds the entire updated sequence back into the Transformer
Repeats Linear → Softmax → Sampling
Generates the next token
And so on…
Until:
the model finishes the sentence
or hits a stop token
or reaches a length limit
That’s how you get complete paragraphs, stories, or explanations.
Step 5: Detokenization → Human-Readable Text
[40, 939, 5306] -> → "I am doing"
Here’s a real example using tiktoken:

Terminal output:

This is the final magic step - turning numbers back into natural language.

So the full output process is:
Linear Layer → Softmax → Pick Next Token → Repeat → Detokenize → Final Answer
That’s how ChatGPT replies to you -
one small token at a time, insanely fast.
Final Thoughts: The Craziest Part? It Writes One Token at a Time.
The wildest part of all this?
LLMs don’t generate full sentences or paragraphs in their heads.
They generate one token at a time:
pick a token
feed it back
predict the next
repeat
insanely fast
That’s it.
That’s the entire magic behind the curtain.
And yet - with just token-by-token predictions, Transformers create:
essays
jokes
poems
stories
explanations
code
full conversations
Wild, right?
But this is only half the story.
Everything you learned here explains inference - how the model uses its knowledge to answer you.
The other half - how the model learns in the first place (training, gradients, loss functions, backprop, massive datasets) - is a world of its own.
And trust me… that one’s crazy too.
So next, we’ll peel back the training side -
how an LLM goes from clueless to genius.
Stay tuned. 😄✌🏻